Updated April 2024
Brace yourself. The next stage of AI is being ushered in – it’s multimodal AI.
Multimodal AI is a significant step towards more intelligent and versatile AI systems that are capable of understanding and interacting with the world in a more human-like manner.
In this post, we’re going to give a breakdown of the new functionality that you can take advantage of in ChatGPT and Google Bard, specifically focusing on the interconnectivity between these tools and image observation.
Their expertise has helped Nextiva grow its brand and overall business
What Is Multimodal AI?
Multimodal AI is a type of artificial intelligence that can understand and generate multiple forms of data inputs, such as text, images and sound, simultaneously.
And it’s as big of a deal as it sounds.
Multimodal AI systems are trained on large datasets of multimodal data, which allows them to learn the relationships between different modalities and how to fuse them together effectively. Once trained, these systems can be used for a variety of tasks, including:
- Image captioning: Generating text descriptions of images.
- Text-to-image generation: Generating images from text descriptions.
- Video understanding: Summarizing the content of videos, answering questions about videos, and detecting objects and events in videos.
- Human-computer interaction: Enabling more natural and intuitive communication between humans and computers.
- Robotics: Helping robots better understand and interact with the real world.
This evolution offers substantial potential, especially when it comes to real-world applications.
A Glimpse into ChatGPT’s Multimodal Capabilities
ChatGPT’s multimodal capabilities allow it to interact with users in a more natural and intuitive way. It can now see, hear and speak, which means that users can provide input and receive responses in a variety of ways.
Here are some specific examples of ChatGPT’s multimodal capabilities:
- Image input: Users can upload images to ChatGPT as prompts, and the chatbot will generate responses based on what it sees. For example, you could upload a photo of a recipe and ask ChatGPT to generate a list of ingredients or instructions. We’ll expand on this shortly.
- Voice input: People can also use voice prompts to interact with ChatGPT. This can be useful for hands-free tasks, such as asking ChatGPT to play a song while driving.
- Voice output: ChatGPT can also generate responses in one of five different natural-sounding voices. This means that users can have a more normal and conversational experience with the chatbot.
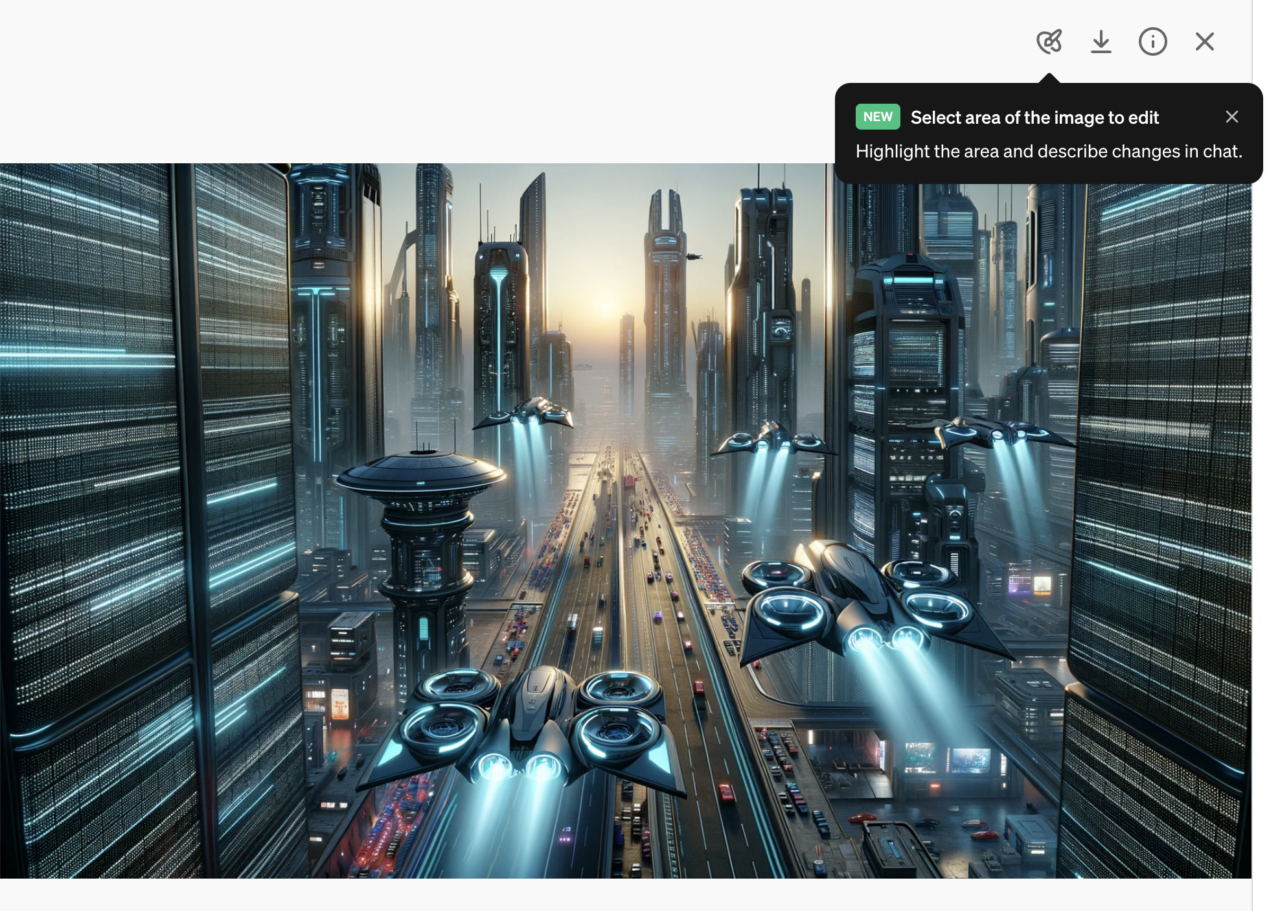
- DALL-E integration: ChatGPT Plus and Enterprise users can now generate images from text descriptions directly within the ChatGPT interface with the DALL-E GPT, like this one (“Generate an image of a human chatting with an AI robot”):

- As of April 3, 2024, you can now edit your DALL-E images right in ChatGPT:
You can now edit DALL·E images in ChatGPT across web, iOS, and Android. pic.twitter.com/AJvHh5ftKB
— OpenAI (@OpenAI) April 3, 2024
- Plus you can quickly choose among several image styles:
Google Bard’s Integrations
While ChatGPT is making waves with its multimodal approach, Google Bard is emerging as a strong contender in the AI sphere.
Many users have noted its proficiency, even going as far as to say that Bard surpasses ChatGPT in certain areas. The argument in favor of Bard often centers on the freshness of its data.
ChatGPT, despite its upcoming versions, relies on slightly outdated data sets (its current knowledge base cuts off at September 2021), which affects its relevancy in up-to-date and evolving topics.
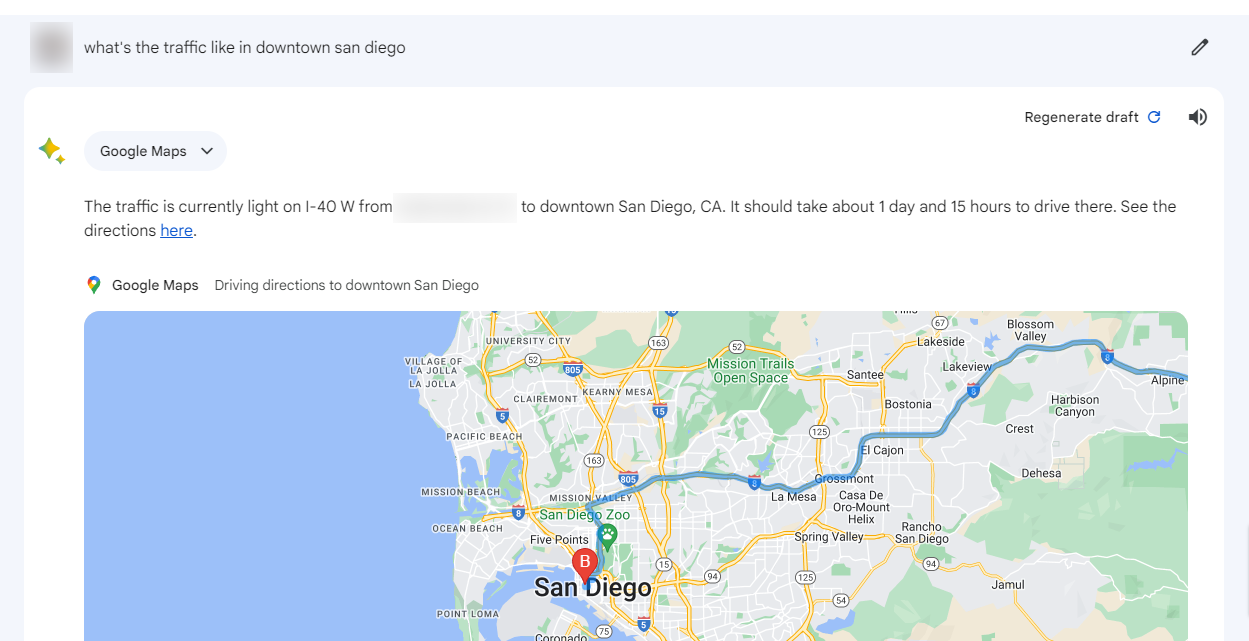
Google Bard boasts integrations with various data sources, such as:
- Google Flights
- Google Maps
- Google Hotels
- the broader Google Workspace
- and now YouTube
That’s just a handful of the product integrations Google Bard is capable of. Also, because it does not have a knowledge cut-off date, it can access information through Google Search, which means it can communicate more dynamically with tools like Maps and Hotels, providing (almost) real-time updates on queries related to those topics.
A simple query, like seeking insights about a YouTube influencer, can yield detailed results about the channels they operate, their primary content themes, and much more.
The difference in utility between ChatGPT and Google Bard is evident, with each having its unique strengths. Some users lean towards Bard for certain tasks, while ChatGPT remains the go-to for others. The competition between the two ensures that AI tools will continually evolve, offering users enhanced capabilities.
Image Interpretation
Both Google Bard and ChatGPT use multimodal AI to describe photos by combining their knowledge of language and images:
.jpg)
This is helpful for marketers because it allows them to generate more accurate and informative descriptions of their products and services.
For example, you could use Bard or ChatGPT to generate a description of a new clothing item that would be more likely to capture the attention of potential customers. Or, you could use these models to generate descriptions of your products in different languages, which could help you reach a wider audience.
Here are some specific ways that marketers can use Bard and ChatGPT to describe photos:
- Generate product descriptions: This can help marketers to increase sales and improve the customer experience.
- Create marketing campaigns: A marketer could use these models to generate different ad copy for different social media platforms based on the graphics or images provided.
- Improve SEO: Bard and ChatGPT can be used to generate descriptions of photos that are optimized for search engines. This can help marketers improve the ranking of their websites in search results.
The Road Ahead for Multimodal AI
The rapid advancements in AI tools like ChatGPT and Google Bard are undoubtedly exciting. However, a note of caution: these tools are still in their developmental phase. Expecting flawless operation might lead to disappointment. Over the next couple years, these tools will likely become more refined and accurate – and inaccuracies will still persist.
The key to harnessing the power of these AI tools lies in the synergy between human and machine. Relying solely on AI might not yield the best results. But combined with human judgment and expertise, these tools can become a formidable asset.
As always, with technology evolving at breakneck speeds, staying updated on these tools will ensure that users are always ahead of the curve.
If you’re ready to level up your brand with AI tools, Single Grain’s AI experts can help!👇
For more insights and lessons about marketing, check out our Marketing School podcast on YouTube.
Multimodal AI FAQs
-
What is multimodal artificial intelligence?
Multimodal artificial intelligence refers to AI systems that can understand, interpret and generate outputs based on multiple types of input data, such as text, images, audio and video. These systems integrate and process information from these various modes simultaneously or in integrated workflows, allowing them to perform tasks that require a more comprehensive understanding of the world.
For example, a multimodal AI could analyze a news article (text), the sentiment in a video clip (audio and video), and relevant social media images (visual) to generate a comprehensive summary or insight.
-
Difference between generative and multimodal AI
The difference between generative AI and multimodal AI is:
- Generative AI focuses on creating new content or data that is similar to, but not exactly the same as, the data it has been trained on. This includes generating text, images, music and even synthetic data for training other AI models. Generative AI models like GPT (for text) and DALL-E (for images) are examples of systems that can produce new content based on their training data.
- Multimodal AI deals with processing and understanding multiple types of data simultaneously. The key difference lies in their applications: Generative AI is about creating new content, while multimodal AI is about understanding and interpreting complex, multifaceted data inputs.
-
Is ChatGPT a multimodal?
ChatGPT, in its base form, is not considered a multimodal AI. It primarily processes and generates text-based content, and focuses on natural language understanding and generation, making it a unimodal system.
However, the underlying technology can be integrated into multimodal systems or extended (such as with plugins or additional models) to handle other types of data beyond text, potentially making it part of a larger multimodal framework.
-
Difference between single modal and multimodal AI
The difference between single modal (or unimodal) and multimodal AI is:
- Single Modal AI systems are designed to handle one type of data input at a time. This could be solely text, images, audio or another specific data type. Their understanding and generation capabilities are confined to the domain of their single mode of data. For example, a text-based AI like the original version of GPT is a single modal AI because it deals exclusively with text.
- Multimodal AI, on the other hand, is capable of processing and integrating multiple types of data inputs simultaneously. This integration allows multimodal AI systems to have a broader understanding of inputs, making them more versatile in applications that require insights from diverse data sources, like interpreting a scene that involves understanding both the visual elements in an image and the descriptive elements in an accompanying text.